|
Valoración de impacto
1. Visión de conjunto Cada vez se concentra más la atención de la evaluación en el efecto final de los programas de planificación familiar y salud, o sea, en el impacto de los programas o las intervenciones. La medición del impacto comprende más que el mero seguimiento de los cambios en los indicadores de resultados, requiere una evidencia empírica de que un cambio observado en los indicadores de resultados es atribuible a un determinado programa o intervención. En otras palabras, requiere evidencia de que el programa o la intervención evaluada ha causado el cambio. Para medir el impacto del programa están disponibles cierta cantidad de métodos y enfoques. Estos difieren en distintos aspectos, como por ejemplo, el número y tipo de supuestos, la solidez de las conclusiones alcanzadas sobre el impacto del programa y los requisitos operacionales y de datos. Este capítulo ofrece una visión de conjunto de los métodos más robustos disponibles para medir el impacto de programas de salud reproductiva, con el objetivo de ofrecer una guía para seleccionar la mejor opción. Las decisiones sobre cómo debería medirse el impacto del programa se deben hacer en la etapa del diseño o del planeamiento de los programas o nuevos ciclos de programas, porque es solo en esta etapa que se tienen disponibles todas las opciones. Una vez que un programa o ciclo de programas está funcionando, se pierde la oportunidad de usar algunos de los diseños de investigación más poderosos y se vuelve necesario recurrir a opciones más débiles. 2. Criterios para guiar la selección del enfoque metodológico Al valorar los diversos métodos descritos en este capítulo, el evaluador debe considerar los siguientes criterios: • Riesgos de perjudicar la validez El criterio más importante para valorar un método es la validez de sus estimaciones del impacto del programa. Aunque todos los métodos son vulnerables a algunos riesgos a la validez, varían considerablemente en términos del número y tipos de riesgos (por ejemplo, riesgos de confusión) a las cuales están sujetos. • Habilidad para aislar los efectos del programa Idealmente, las medidas del impacto del programa incluyen solo resultados directamente atribuibles al programa. En la mayoría de los escenarios, factores como las fuerzas de desarrollo económico, programas sociales múltiples, estructura demográfica cambiante y la presencia de actividades de planificación familiar fuera del programa complican los intentos de medir el impacto del programa. Los métodos difieren en la medida en que el evaluador puede aislar los efectos del programa de las influencias de otros factores. Los métodos preferibles son aquellos más eficientes para aislar estos efectos. • Costos Esto se refiere a los costos de la recolección y análisis de datos. En igualdad de condiciones, se prefieren los métodos de menor costo. Sin embargo, en la mayoría de los casos, los métodos difieren sobre los otros criterios, tanto como en el costo. Es por eso que deben tomarse decisiones sobre el costo-beneficio. • Datos requeridos Los métodos varían considerablemente en cuanto a los datos requeridos. Aparte de las diferencias en el volumen de datos requeridos, algunos métodos necesitan datos que son muy difíciles de recolectar y/o son más vulnerables a errores de medición que otros métodos. Esto puede aumentar el riesgo de que el error de medición oscurezca los efectos de los programas o exagere la magnitud del impacto logrado realmente. • Percepción de la naturaleza de las trayectorias causales Los métodos varían mucho en relación a la cantidad de información que proporcionan sobre cómo los insumos son transformados a productos y resultados como parte del proceso de medición del impacto. Aunque no se requiere para la medición del impacto, esta información de los mecanismos causales provee una percepción muy útil de cómo pueden mejorarse los programas en ciclos de programa subsiguientes. • Tipos de indicadores de resultados Algunos métodos están diseñados específicamente para la medición de cierto tipo de resultados. • Requisitos en el grado de control del programa Los experimentos diseñados como tales (los experimentos al azar y en menor grado los estudios cuasi-experimentales) proveen la evidencia más importante del impacto del programa, pero también requieren condiciones de mayor control en la forma en la cual el programa es evaluado y la forma en que se efectúan otras intervenciones. Los estudios no experimentales no requieren que los programas sean implementados de manera específica para proveer mediciones válidas del impacto del programa, pero generalmente requieren mayor cantidad de datos y análisis más complejos para producir resultados válidos. • Recursos y destrezas técnico/estadísticas requeridas Aunque todos los métodos considerados requieren de conocimiento y destrezas básicas en las áreas de la investigación y la estadística, algunos métodos y enfoques requieren destrezas relativamente avanzadas y en algunos casos software especializado. 3. Métodos Preferidos Pruebas aleatorias | Cuasi-experimentos
1. ¿Qué son cuasi-experimentos? El término "cuasi-experimento" se refiere a diseños de investigación experimentales en los cuales los sujetos o grupos de sujetos de estudio no están asignados aleatoriamente. Los diseños cuasi-experimentales más usados siguen la misma lógica e involucran la comparación de los grupos de tratamiento y control como en las pruebas aleatorias. En otros diseños, el grupo de tratamiento sirve como su propio control (se compara el "antes" con el "después") y se utilizan métodos de series de tiempo para medir el impacto neto del programa (Rossi y Freeman, 1993). Aunque los cuasi-experimentos son más vulnerables a las amenazas a la validez que las pruebas aleatorias, los cuasi-experimentos no requieren asignaciones aleatorias a los grupos experimentales y por eso son generalmente más factibles que las pruebas aleatorias. 2. Ventajas de los cuasi-experimentos Las ventajas principales del diseño de grupo control no equivalente son: Provee una aproximación al experimento aleatorio cuando la aleatoriedad no es posible. Es versátil. Como las pruebas aleatorias, los cuasi-experimentos pueden usarse para medir resultados a nivel poblacional o de programa. Cuando se diseñan, controlan y analizan apropiadamente, los cuasi-experimentos pueden ofrecer una evidencia casi tan fuerte del impacto del programa como la de las pruebas aleatorias y más fuerte que la mayoría de los estudios no experimentales. 3. Limitaciones de los cuasi-experimentos El diseño de grupo control no equivalente está sujeto a los mismos supuestos generales y limitaciones que las pruebas aleatorias expuestos anteriormente (fuera de los que contemplan la aleatoriedad). Además: El cuasi-experimento es más vulnerable a los sesgos de selección, o sea, que el grupo de tratamiento puede diferir del grupo control en características que están correlacionadas con los resultados estudiados, distorsionando los resultados del impacto. Depende mucho de los métodos estadísticos multivariables y es, por lo tanto, sensible al uso de modelos estadísticos apropiados y al tratamiento correcto de los problemas de estimación estadística. En la práctica, los estudios cuasi-experimentales a menudo pueden compensar las diferencias en las características clave de los grupos experimentales a través del pareo y el análisis multivariable. Sin embargo, una preocupación latente es que los grupos experimentales difieran en factores no observados que influyen en los resultados del estudio. A diferencia de los efectos distorsionantes en factores observables y que pueden tomarse en cuenta mediante el pareo y la introducción de variables de control en modelos estadísticos multivariables, los factores no observables (por ejemplo, predisposición o motivación diferencial) no pueden ser compensados de esta forma y pueden conducir a estimaciones de impacto de programa equivocadas y/o sesgadas. Este factor de heterogeneidad "no observada" es, de hecho, una preocupación en todos los diseños de estudio que no sean pruebas aleatorizadas.
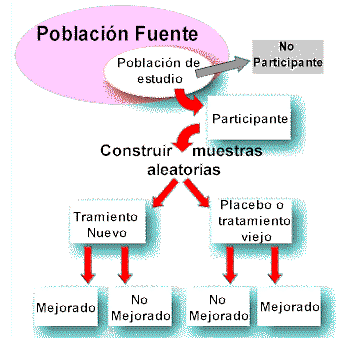
1. ¿Qué son pruebas aleatorias? En una prueba aleatoria se da una comparación directa de dos (o más) grupos de tratamiento, uno de los cuales sirve como un control sin tratamiento. El grupo control puede permanecer sin tratamiento (placebo) o someterse a un régimen establecido contra el cual, el nuevo régimen será valorado (control activo). Está ampliamente aceptado entre los investigadores dedicados a la evaluación que la prueba aleatoria es la "norma de oro" para medir lo que ha ocurrido como resultado de un programa o intervención. 2. Diseño básico de una prueba aleatoria La idea fundamental de una prueba aleatoria es muy simple. En una prueba aleatoria, los sujetos o grupos de estudio son asignados aleatoriamente a los grupos de "tratamiento" o de "control", o sea, una vez que los sujetos o grupos de sujetos que van a ser estudiados son seleccionados, algunos son asignados al grupo de tratamiento y otros al grupo control (o de comparación) en forma aleatoria. (Ver Figura 1). Es preferible que las pruebas aleatorias se realicen "a ciegas", de manera que los sujetos (y a veces, también, los investigadores) no sepan si un sujeto de estudio está en un grupo de tratamiento o de control.
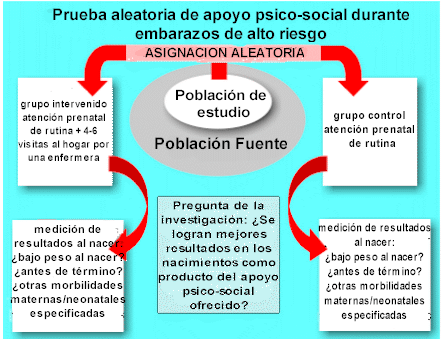
3. Construcción de muestras aleatorias La construcción de muestras aleatorias deja que la casualidad determine la asignación de sujetos experimentales a los grupos de tratamiento o de control. Por lo tanto, elimina por completo el juicio o selección humana del proceso de asignación. Los ejemplos de muestras aleatorias incluyen el lanzamiento de una moneda al aire para determinar la asignación de cada sujeto o usar una tabla de números al azar para asignar sujetos. La construcción de muestras aleatorias reduce la posibilidad de que hayan diferencias significativas (por ejemplo, en edad, sexo, raza, peso, color del cabello o riesgo de enfermedad) entre dos grupos aleatorios, siempre y cuando los grupos sean suficientemente grandes para producir grupos estadísticamente estables de 100 o más sujetos. El propósito principal de la construcción de muestras aleatorias es asegurar que antes de que uno de los grupos empiece el tratamiento o la intervención, los dos grupos estén igualmente expuestos al riesgo de desarrollar el resultado de interés. Por lo tanto, con una muestra suficientemente grande, la construcción de muestras aleatorias aumenta la posibilidad de aislar sin ambigüedad los efectos de un programa o intervención distribuyendo los factores extraños por igual entre los grupos de comparación. Esto equivale a asegurar que los grupos de tratamiento y control sean iguales respecto a todos los factores, exceptuando la exposición al programa evaluado. Esto representa una ventaja enorme sobre otros métodos de medición del impacto del programa. 4. Asignación "a ciegas" La asignación "a ciegas" ayuda a asegurar que, una vez que los sujetos están integrados en muestras aleatorias, su comportamiento y el de los investigadores del estudio no va a estar afectada por el hecho de saber que los sujetos pertenecen a un grupo de tratamiento o a un grupo control. De esta forma, la asignación "a ciegas" contribuye a la validez científica de un estudio en el período posterior a la contrucción de las muestras aleatorias. La asignación "a ciegas" iguala el efecto placebo entre los grupos de estudio. Ejemplo: si un sujeto sabe que está en el grupo placebo y empieza a experimentar un empeoramiento de la condición de la enfermedad, estaría muy tentado a abandonar el estudio. De manera semejante, los sujetos que saben que están recibiendo el nuevo tratamiento pueden sentirse reforzados en cuanto a su padecimiento y mejorar realmente debido a su actitud positiva, más que por efecto del efecto específico del tratamiento. Ejemplo: los médicos cuyos pacientes están participando en el estudio podrían intervenir si saben que su paciente está en el grupo placebo y está empeorando. La asignación "a ciegas" puede ser "simple" o "doble". En una prueba "a ciegas" simple, solo los sujetos del estudio desconocen su ubicación (por ejemplo, en la comparación de distintas técnicas quirúrgicas). En una prueba "a ciegas" doble, los sujetos del estudio y el personal del estudio desconocen la ubicación de los sujetos del estudio. 5. Ejemplo de una prueba aleatoria Se muestra a continuación un ejemplo de una prueba aleatoria: Una prueba aleatoria de apoyo psicosocial durante embarazos de alto riesgo. J. Villar et al. N Engl J Med 1992; 327:1266-71. Una prueba aleatoria para evaluar un programa de visitas sociales diseñado para proveer apoyo psicosocial durante embarazos de alto riesgo fue llevada a cabo en cuatro centros en América Latina. La población de estudio se compuso de 2235 mujeres con un riesgo mayor al promedio de parir un niño con bajo peso al nacer. Las mujeres fueros asignadas al azar en dos grupos (intervención y control) antes de la semana 20 de embarazo y continuó hasta el nacimiento de su niño. Ver la Figura 2 para mayores detalles.
6. Ventajas de las pruebas aleatorias Es el más parecido a un experimento científico controlado.
7. Limitaciones de las pruebas aleatorias
Existe al menos otra consideración práctica que puede limitar la utilidad de los experimentos aleatorios para la medición del impacto del programa: podría no tener sentido, desde el punto de vista programático, localizar programas o intervenciones en forma aleatoria. De hecho, los programas a menudos son dirigidos a áreas geográficas o subgrupos poblacionales por dos razones diametralmente opuestas: (1) atender a grupos históricamente peor servidos o (2) ofrecer el programa a los grupos más receptivos. Referencias: (1) Medical Epidemiology 1996, 2nd Edition, Raymond S. Greenberg (2) Epidemiology, 1996, 1st Edition, Leon Gordis Si usted quiere aprender más sobre el tema de las pruebas aleatorias, en el vínculo siguiente está disponible un material en español.
|
|